
Mr. Naraku
Unexpert Bosun
This post discusses mundane afternoons, document metadata, and Exiftool, a useful paleographical instrument for those who enjoy reading between the lines. I recently picked up one or two new tricks while digging up treasure chests from the deep sands of the internet. After finding all that gold, one could not help but ask who put it there in the first place.
Here's the contents:
The story of the treasure chest
I was recently venturing through uncharted territories of the internet when I stumbled upon a mysterious magnet link claiming to lead to a variety of materials from many particularly expensive advanced cybersecurity courses. I am not going to disclose the name of the issuing organization, let’s just say it begins with an S- and it ends with -ANS. Do you have any remote idea of how much such types of courses can cost nowadays? We are talking about thousands of bucks, for each single one of them. When knowledge is so expensive, one can either choose to remain an ignorant goat or click on the magnet link and open the P2P session right away. Of course, I didn't choose the latter option. I am an honest, goat-looking, law-abiding citizen and I profoundly discourage copyright infringement. But for the sake of what comes next, let’s pretend I did open the chest and got my hands on the gemstones and the jewelry. After the burst of euphoria, two questions would come to mind: (a) what am I going to use all this stolen fortune for? and (b) who the hell put it there in the first place – i.e., what other pirate am I stealing it from? To answer this second dilemma, if I did open the chest, I’d use document metadata analysis tools, such as Exiftool or Strings. And since I have recently learned some tricks with both, I thought I could make a post about them.

Picture of a goat
What we look for in metadata
The stuff we use to create, modify and handle files embed a bunch of metadata within such files. In paleography, the type of paper and writing materials can be analyzed to determine the historical dating and context of an antique artifact. In some sense, that’s metadata too. We do the same, but with digital artifacts. So what do we look for? Well anything, really… but in particular:
- Usernames. Usernames related to the analyzed file are the starting point for further investigations. Also, they can be pretty useful when it comes to password guessing.
- E-mail addresses. An attacker would use these for phishing, a tester for ethical phishing tests. One could also use the recovered addresses to look for leaked credentials from previous breaches (here, I recommend a quick check on haveibeenpwned.com first).
- File system paths. Knowing the full path of the original file when it was created can reveal hints about the OS, important critical directories, and common practices of the given user.
- Client-side software in use. Knowing which tools and programs were used to handle the analyzed files can be cool (e.g., office suite, PDF-generating tool, camera models used to take pictures, etc). Tools and tools versions might indicate vulnerabilities, that goes without saying.
- Other information. Other useful information about the file (e.g., undo information, previous revisions, hidden collapsed column in a spreadsheet) or who created it (e.g., timestamps).
Typically, in a network VA/PT, the initial phases of reconnaissance involve looking for useful bits of information about the target organization through document metadata analysis. In that case, documents are retrieved in three main ways:
- By asking politely,
- Implicitly, during the formal preparation of the test (e.g., rules of engagement agreements, scope information, non-disclosure agreements, contracts, policies, etc.),
- By scraping the website of the organization.
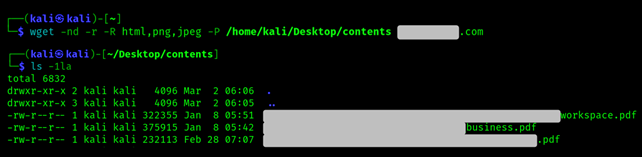
The easiest way of scraping is with wget, for example like this:
wget -nd -r -R html,png,jpeg -P [/../MYPATH] [target domain]
Where...
-nd stands for “no directories", it means you don’t wanna create a hierarchy of directories when downloading files.
-r stands for follow recursively all links within the specified URL until you reach the end of the links.
-R html, png, jpeg means reject (-R) downloading the files with the specified extensions.
P [/…/MY PATH]- specifies the path to the directory where the downloaded files will be stored.
[target domain] is clearly the domain of the website from which to pull the files.
For example:
Alternatively, if you want to specify the extensions to pull instead of the ones to reject, you can substitute the -R with the -A option.
What we are going to use
Anyways, we are not going to scrape anything here. Let's instead assume that we already got what we want to inspect. These are the two metadata analysis tools we are going to use:
- ExifTool (from Phil Harvey, runs on Linux, Windows and there should also be a version online)
- The strings command (for Unix-like systems, simply displays printable text from files and it’s useful for finding unstructured data)
The Indonesian thief
Exiftool is quite straightforward. For example, let's go back to the hypothetical treasure chest and pick the first thing that comes to hand and let's run the following.
exiftool -a -G1 [FILE]
Where -a means we want to allow duplicate tags to be extracted, and -G1 specifies to print the group name for each tag.
We'd obtain something like this:
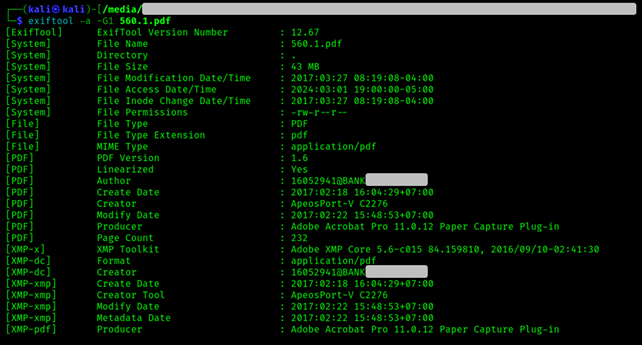
One command and we are already at a point where many questions arise.
Who the hell is 16052941@BANK[...]? Let’s first search for domains that sound like BANK[…] and go from there. If we don't find anything, we can use waybackmachine or similar archives. We are lucky enough though, it turns out BANK[...] is some bank in Indonesia.
Let’s now look at the timestamps. If we focus on the pdf metadata we see it was created in February 2017 (2017:02:18 16:04:29+07:00). If we instead look at the system metadata, the modification date/time indicates March 2017 (2017:03:27 08:19:08-04:00). I am not sure, but I think the system metadata here indicates modifications at system level (so at inode level) while the pdf metadata refers to actual changes in the pdf file. So, for example, someone might have changed the pdf content in February and then renamed the same pdf file in March. This is all speculation, but who cares.
Notice how the pdf was created in a UTC+07:00 time zone, which is Indochina Time (ICT).. This region includes Vietnam, Cambodia, Laos, Thailand and (guess what) parts of Indonesia. So yes, the guy was probably an employee at this Indonesian BANK[…].
UTC+07:00
We said last time someone modified the file at system level was 2017:03:27 08:19:08-04:00. Hey wait, here the time zone has changed again… now it’s UTC -04:00, which according to Wikipedia...
"is observed in the Eastern Time Zone (e.g., in Canada and the United States) during the warm months of daylight saving time, as Eastern Daylight Time. The Atlantic Time Zone observes it during standard time (cold months). It is observed all year in the Eastern Caribbean and several South American countries”.
What happened? Did our file move? Did the owner? We'll never know :c
UTC-04:00
Let’s focus now on that ApeosPort-V C2276 in the creator tag. What the hell is that? After a quick search on google, it appears to be a printer. To be precise, the 2013 Fujifilm enterprise printer, possibly used for scanning the physical materials of the stolen courses. The scans have been later processed with the Adobe plugins (Adobe Acrobat Pro 11.0.12 Paper Capture Plug-in) turning them into pdf for the joy of the internet. What intelligence do we get from this? I don’t know, but look at this ApeosPort-V C2276 monster:

ApeosPort-V C2276
We now know that the leaked pdf probably comes from a guy working in an Indonesian bank called BANK[…]. The guy scanned the physical course book with his company ApeosPort-V C2276 printer and then turned it into a pdf using Adobe Acrobat. We don’t know much else about his identity – for now – but, considering the cost of the course whose materials he has publicly disclosed (about 9000 bucks), one could assume he held a crucial position within the organization and it was the bank itself that decided to pay for this type of specialized education. Achieving such elevated ranks typically requires years of experience, suggesting that the individual - back in 2017 - must have already had a certain level of seniority within the organization. Finally – and this is perhaps the first thing that comes to mind – it is pretty probable that, after completing the course, the guy must have wanted to advertise this new achievement, maybe by posting the certification credentials within a public CV or directly on a Linkedin profile. That’s where we are going to play some "Guess Who?".
That's enough. I am wasting too much time on this man. I am not even sure he's a man. I don't care. I wanted to talk about metadata analysis, so let's continue with Exiftool.

Guess who?
Exiftool to cast wider nets
We might have many files to inspect. So, what if we want to be faster? Let’s see some other useful spells. We can Exiftool on a whole directory, for all the contained files, recursively (-r). And then we grep just what we are interested in. Like this:
exiftool -r [DIRECTORY] | grep ‘Something’
So, for example, instead of picking whatever from the treasure chest, let’s run exiftool on the whole fortune and grep for the Author tag. We are going to have a lot of duplicates, so let’s remove them by piping sort -u.
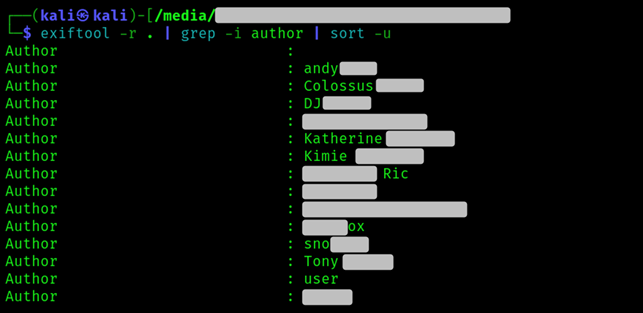
Look how much fish we got. Time to start looking for these people’s face. I spare you that part of our investigation, but it’s literally the easiest thing to do. People really seem to enjoy posting pictures of themselves.
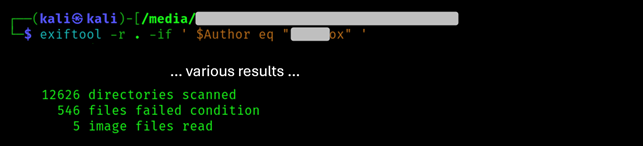
Note that if we want to focus our analysis on the precise files handled by – for example – the user […]ox, we can just use the following syntax:
exiftool [DIRECTORY] -if ' [TAG] eq "something" '
For example:
Strings, regex and phishing
Strings command simply displays printable text from files. So let’s do it.
strings -n8 -el [FILE] | grep -i ‘something’
With -n8 we set minimum length of strings to 8. We can change this too, clearly. With -e (“encoding”) we specify the character encoding of the strings to be displayed. We should set this as “l” (lowcase L, for little endian 16 bit characters) or as “b” (big endian 16 bit characters). If we omit -e option, strings looks for ASCII only. Little endian and big endian refer to the order by which we allocate the bytes in the virtual addresses of the RAM. I am not going to delve into this, also because I am an ignorant chimp when it comes to memory. Let’s just say that, to be safe, we normally run strings three times: once with -el, once with -eb, once without the option.
If we run the following, we can observe how we pretty much find the same evidence uncovered by Exiftool.

If you want to search specifically for anything that matches an email address, then you can use this regex (-E):
strings [FILE] | grep -Eo '[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,4}'
Or even better, you can do this recursively, starting from a certain directory, like this:
find . -type f -exec strings {} \; | grep -Eo '[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
Where...
find . -type f stands for “find me any file in the directory and subdirectories”;
-exec strings {} \; stands for “use strings on each file you find”;
| grep -Eo [Regex Pattern] stands for “within the strings output, search whatever matches the regex pattern (-E) and print out only that (-o), not the whole line”.
Here’s an example of what happens if we run it on the treasure chest.
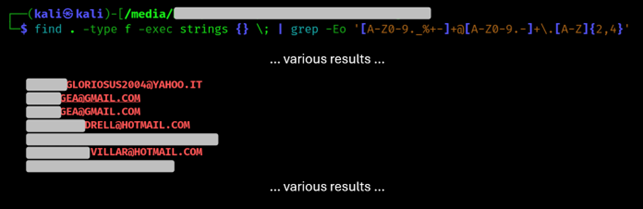
At this point, for an attacker, phishing would be right around the corner. But we are not interested in that.
And if we want to look for paths? Nothing changes, the command is always the same. :
find . -type f -exec strings {} \; | grep -E 'C:\\'
Or more simply:
find . -type f -exec strings {} \; | grep -E '\\'
👽 Related links 👽
If you wanna know more about this stuff, these may be useful resources to begin with.
ExifTool 12.77
User Contributed Perl Documentation
Strings manual
Linux and UNIX Man Pages